





La historia detrás de Active Threat Intelligence de Barracuda
Hace un tiempo, en una de nuestras sesiones de lluvia de ideas, mientras los equipos discutían el siguiente nivel de evolución de nuestros productos, se puso en evidencia que la detección y protección contra amenazas nuevas y emergentes requería un análisis intensivo de datos a gran escala. Ese análisis tendría que predecir el riesgo de los clientes y hacerlo de forma eficiente y rápida si queríamos evitar que se produzcan acciones hostiles.
A medida que analizábamos los requisitos, nos dimos cuenta de que, para poder proteger contra atacantes avanzados como los bots, necesitábamos construir una plataforma que pudiera analizar el tráfico de las sesiones web, correlacionarlo con los datos de las sesiones y, para muchas cosas, a través de toda la base de clientes. También nos dimos cuenta de que muchas partes del sistema debían funcionar en tiempo real, algunas casi en tiempo real, y otras podían tener una fase de análisis mucho más prolongada.
Hace unos años presentamos Barracuda Advanced Threat Protection (BATP) para la protección contra ataques de malware de día cero en toda la línea de productos de Barracuda. Esta capacidad (analizar archivos para detectar el malware mediante varios motores además del sandboxing) se introdujo en los productos de seguridad de aplicaciones de Barracuda para proteger aplicaciones como los sistemas de procesamiento de pedidos donde terceros subían archivos. Este fue el primer intento de utilizar una capa basada en la nube para realizar análisis avanzados que habría sido difícil de integrar en los dispositivos de web application firewall.
Pero aunque la capa de nube de BATP podía gestionar millones de escaneos de archivos, necesitábamos un sistema que pudiera almacenar grandes cantidades de metainformación para que pudiera ser analizada y así identificar amenazas nuevas y en evolución. Esto nos inició el camino hacia la próxima plataforma de inteligencia contra las amenazas.
Cómo funciona Active Threat Intelligence
La plataforma Barracuda Active Threat Intelligence es nuestra respuesta. La plataforma se basa en un lago de datos masivo, que puede manejar el procesamiento de flujos, así como el procesamiento por lotes de datos. Procesa millones de eventos por minuto en diversas geografías y proporciona inteligencia utilizada para detectar bots y ataques del lado del cliente, además de ofrecer información para proteger contra esos vectores de amenazas. Asimismo, Barracuda Active Threat Intelligence está diseñado con una arquitectura abierta para poder evolucionar rápido y abordar amenazas más recientes.
Hoy, la plataforma Barracuda Active Threat Intelligence recibe datos de los motores de seguridad en el Barracuda Web Application Firewall y WAF-as-a-Service, así como de otras fuentes. A medida que se reciben los eventos, se enriquecen utilizando fuentes de amenazas de origen colectivo y otras bases de datos de inteligencia. El análisis detallado de estos eventos, tanto de forma individual como formando parte de una sesión de usuario, se utiliza para categorizar a los clientes como humanos o bots.
Los canales de análisis de datos utilizan varios motores y modelos de aprendizaje automático para analizar diversos aspectos del tráfico y llegar a sus recomendaciones, que al final se unen para producir el veredicto final.
Formas en que Active Threat Intelligence le ayuda a proteger sus aplicaciones
Además de admitir todos los análisis necesarios para la Protección Avanzada contra bots, la plataforma Active Threat Intelligence también se usa para nuestras últimas ofertas: la Protección del Lado del Cliente y el Motor de Configuración Automatizado.
Active Threat Intelligence rastrea cualquier recurso externo que pueda utilizar la aplicación, como un JavaScript externo o una hoja de estilo. Al mantener un seguimiento de los recursos externos, nos aseguramos de ser conscientes de la superficie de amenaza y podemos protegernos contra ataques como MageCart y otros.
Dado que los metadatos recopilados son extremadamente ricos, podemos extraer información adicional para ayudar a los administradores proporcionándoles recomendaciones de configuración basadas en el tráfico real que llega a sus aplicaciones.
Esta plataforma ha sido fundamental para ayudarnos a crear la próxima generación de capacidades de protección que requieren nuestros clientes. Continuamos aprovechando esta plataforma escalable para obtener información detallada sobre los patrones de tráfico, el consumo de aplicaciones y mucho más. Manténganse al tanto de los blogs de nuestros equipos de ingeniería, que les explicarán cómo desarrollamos Barracuda Advanced Threat Intelligence.

Anshuman Singh es Director Senior de Product Management en Barracuda. Conecte con él en LinkedIn aquí.
La evolución del canal de datos
El canal de datos es el pilar central de las aplicaciones modernas intensivas en datos. En el primer artículo de esta serie, examinaremos la historia del canal de datos y cómo han evolucionado estas tecnologías a lo largo del tiempo. Más adelante describiremos cómo estamos aprovechando algunos de estos sistemas en Barracuda, algunos aspectos a considerar al evaluar los componentes del canal de datos, y algunos ejemplos novedosos de aplicaciones que le ayudarán a comenzar a construir e implementar estas tecnologías.
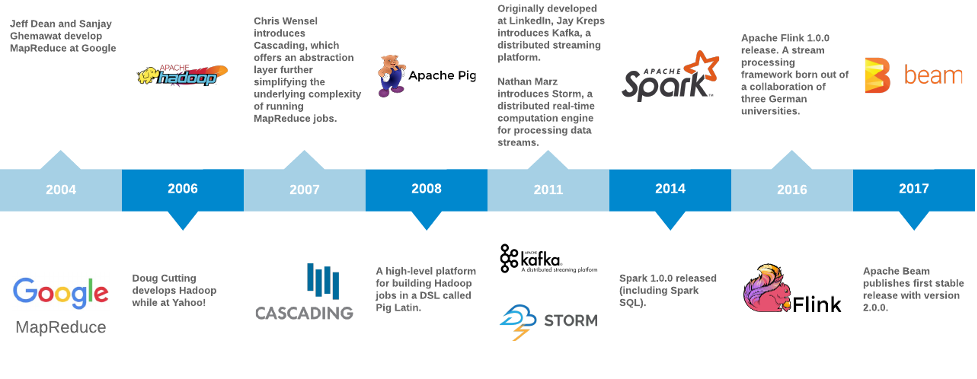
MapReduce
En 2004, Jeff Dean y Sanjay Ghemawat de Google publicaron MapReduce: Simplified Data Processing on Large Clusters. Describieron MapReduce como:
«[…] un modelo de programación y una implementación asociada para procesar y generar grandes conjuntos de datos». Los usuarios especifican una función de mapeo que procesa un par clave/valor para generar un conjunto de pares clave/valor intermedios, y una función de reducción que combina todos los valores intermedios asociados con la misma clave intermedia.
Con el modelo MapReduce, pudieron simplificar la carga de trabajo paralelizada para generar el índice web de Google. Esta carga de trabajo se programó contra un clúster de nodos y ofrecía la capacidad de escalar para mantenerse al día con el crecimiento de la web.
Una consideración importante de MapReduce es cómo y dónde se almacenan los datos en el clúster. En Google, esto fue denominado Google File System (GFS). Al final, una implementación de código abierto de GFS del proyecto Apache Nutch se integró en una alternativa de código abierto a MapReduce llamada Hadoop. Hadoop surgió de Yahoo! en 2006. (El nombre de «Hadoop» se lo puso Doug Cutting en honor a un elefante de juguete que era de su hijo).
Apache Hadoop: una implementación de código abierto de MapReduce
![]()
Hadoop alcanzó una gran popularidad, y pronto los desarrolladores comenzaron a introducir abstracciones para describir tareas a un nivel más alto. Mientras que las funciones de entrada, mapeador, combinador y reductor de los trabajos se especificaban antes con mucha parafernalia (normalmente en Java simple), ahora los usuarios tienen la capacidad de construir canales de datos utilizando fuentes, receptores y operadores comunes con Cascading. Con Pig, los desarrolladores especificaron trabajos a un nivel aún más alto utilizando un nuevo lenguaje específico de dominio llamado Pig Latin. Consulte el recuento de palabras en Hadoop, Cascading (2007) y Pig (2008) para compararlos.
Apache Spark: Un motor de análisis unificado para el procesamiento de datos a gran escala
En 2009, Matei Zaharia comenzó a trabajar en Spark en la UC Berkeley AMPLab. Su equipo publicó Spark: Cluster Computing with Working Sets en 2010, que describía un método para reutilizar un conjunto de trabajo de datos en múltiples operaciones paralelas, y lanzó la primera versión pública en marzo de ese año. Un artículo de seguimiento de 2012 titulado Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing ganó el premio al mejor artículo en el Simposio de USENIX sobre Diseño e Implementación de Sistemas en Red. El documento describe un enfoque novedoso llamado Resilient Distributed Datasets (RDDs), que permite a los programadores aprovechar los cálculos en memoria para lograr aumentos de rendimiento de órdenes de magnitud para algoritmos iterativos como PageRank o aprendizaje automático en el mismo tipo de trabajos cuando se construyen en Hadoop.
Además de las mejoras de rendimiento para los algoritmos iterativos, otra innovación importante que introdujo Spark fue la capacidad de realizar consultas interactivas. Spark aprovechó un intérprete interactivo de Scala para permitir que los científicos de datos interactúen con el clúster y experimenten con grandes conjuntos de datos mucho más rápido que el enfoque existente de compilar y enviar un trabajo de Hadoop y esperar los resultados.
Sin embargo, hay un problema persistente: la entrada en estos trabajos de Hadoop o Spark solo considera datos de una fuente delimitada (no considera los nuevos datos entrantes en el tiempo de ejecución). El trabajo está dirigido a una fuente de entrada; determina cómo descomponer el trabajo en partes o tareas paralelizables, ejecuta las tareas en todo el clúster simultáneamente y, finalmente, combina los resultados y almacena la salida en algún lugar. Funcionó muy bien para trabajos como la generación de índices de PageRank o la regresión logística, pero no era la herramienta adecuada para otros muchos trabajos que necesitaban trabajar con una fuente no delimitada o de transmisión, como el análisis de flujo de clics o la prevención del fraude.
Apache Kafka: una plataforma de streaming distribuida
En 2010, el equipo de ingeniería de LinkedIn estaba llevando a cabo la tarea de reestructurar los fundamentos de la popular red social profesional [Una breve historia de Kafka, la plataforma de mensajería de LinkedIn]. Al igual que muchos sitios web, LinkedIn pasó de una arquitectura monolítica a una con microservicios interconectados. Sin embargo, la adopción de una nueva arquitectura basada en un canal universal construida sobre un registro de confirmaciones distribuido llamado Kafka permitió a LinkedIn afrontar el desafío de gestionar streams de eventos en casi tiempo real y a una escala considerable. Kafka fue nombrado así por el ingeniero principal de LinkedIn, Jay Kreps, porque era «un sistema optimizado para la escritura», y Jay era un gran admirador de la obra de Franz Kafka.
La principal motivación de Kafka en LinkedIn fue desacoplar los microservicios existentes para que pudieran evolucionar de forma más libre e independiente. Anteriormente, cualquier esquema o protocolo utilizado para habilitar la comunicación entre servicios había condicionado la coevolución de los servicios. El equipo de infraestructura de LinkedIn se dio cuenta de que necesitaban más flexibilidad para que los servicios evolucionaran de forma independiente. Diseñaron Kafka para facilitar la comunicación entre servicios de manera asíncrona y basada en mensajes. Debía ofrecer durabilidad (almacenar mensajes en el disco), ser resistente a fallos de red y nodos, ofrecer características casi en tiempo real y escalar horizontalmente para poder gestionar el crecimiento. Kafka satisfizo estas necesidades al proporcionar un log distribuido (consulte The Log: Lo que todo ingeniero de software debe saber sobre la abstracción unificadora de los datos en tiempo real).
Para 2011, Kafka se había convertido en código abierto, y muchas empresas lo estaban adoptando en masa. Kafka innovó en las abstracciones previas similares de colas de mensajes o sistemas pub-sub, como RabbitMQ y HornetQ, de varias maneras clave:
- Los temas de Kafka (colas) están divididos para escalar en un clúster de nodos de Kafka (llamados «brokers»).
- Kafka utiliza ZooKeeper para la coordinación de clústeres, alta disponibilidad y conmutación por error.
- Los mensajes se almacenan en el disco durante períodos de tiempo muy prolongados.
- Los mensajes se consumen en orden.
- Los consumidores mantienen su propio estado en relación con el desplazamiento del último mensaje consumido.
Estas propiedades liberan a los productores de tener que mantener un estado respecto al reconocimiento de cualquier mensaje individual. Los mensajes ahora se pueden mandar en streaming al sistema de archivos a alta velocidad. Dado que los consumidores son responsables de mantener su propio desplazamiento en el tema, podrían gestionar las actualizaciones y los fallos con facilidad.
Apache Storm: sistema de computación distribuida en tiempo real
Mientras tanto, en mayo de 2011, Nathan Marz estaba firmando un acuerdo con Twitter para que adquiriera su empresa BackType. BackType era una empresa que «desarrolló productos de análisis para ayudar a las empresas a comprender su impacto en las redes sociales tanto históricamente como en tiempo real» [History of Apache Storm and Lessons Learned]. Una de las joyas de la corona de BackType era un sistema de procesamiento en tiempo real denominado «Storm». Storm introdujo una abstracción denominada «topología», mediante la cual las operaciones de stream se simplificaron de manera similar a lo que MapReduce había logrado para el procesamiento por lotes. Storm se hizo conocido como «el Hadoop del tiempo real» y rápido ascendió a los primeros puestos de GitHub y Hacker News.
Apache Flink: Cálculos con estado sobre streams de datos
Flink también hizo su debut público en mayo de 2011. Tiene sus raíces en un proyecto de investigación denominado «Stratosphere» [http://stratosphere.eu/], que fue un esfuerzo colaborativo entre varias universidades alemanas. Stratosphere fue diseñado con el objetivo de «mejorar la eficiencia del procesamiento masivo de datos en paralelo en plataformas de infraestructura como servicio (IaaS)» [http://www.hpcc.unical.it/hpc2012/pdfs/kao.pdf].
Al igual que Storm, Flink ofrece un modelo de programación para describir flujos de datos (denominados «Jobs» en la terminología de Flink) que incluyen un conjunto de streams y transformaciones. Flink incluye un motor de ejecución para paralelizar eficazmente la tarea y programarla en un clúster gestionado. Una propiedad única de Flink es que el modelo de programación facilita tanto las fuentes de datos delimitadas como las no delimitadas. Esto significa que la diferencia de sintaxis entre un trabajo que se ejecuta una sola vez y obtiene datos de una base de datos SQL (lo que tradicionalmente podría haber sido un trabajo por lotes) y un trabajo que se ejecuta continuamente sobre datos en streaming de un tema de Kafka es mínima. Flink entró en el proyecto de incubación de Apache en marzo de 2014 y fue aceptado como un proyecto de alto nivel en diciembre de 2014.
En febrero de 2013, se lanzó la versión alfa de Spark Streaming con Spark 0.7.0. En septiembre de 2013, el equipo de LinkedIn liberó como código abierto su framework de procesamiento de streams «Samza» con esta publicación.
En mayo de 2014, se lanzó Spark 1.0.0, e incluyó el debut de Spark SQL. Aunque la versión actual de Spark en ese momento solo ofrecía capacidad de streaming dividiendo una fuente de datos en «microlotes», ya estaban establecidas las bases para ejecutar consultas SQL como aplicaciones de streaming.
Apache Beam: Un modelo de programación unificado para trabajos por lotes y en streaming
En 2015, un colectivo de ingenieros de Google publicó un artículo titulado El modelo de flujo de datos: un enfoque práctico para equilibrar la corrección, la latencia y el coste en el procesamiento de datos a gran escala, ilimitados y fuera de orden. Una implementación del modelo Dataflow se puso a disposición comercial en Google Cloud Platform en 2014. El SDK principal de este trabajo, así como varios conectores de E/S y un ejecutor local, fueron donados a Apache y se convirtieron en el lanzamiento inicial de Apache Beam en junio de 2016.
Uno de los pilares del modelo de Dataflow (y de Apache Beam) es que la representación del canal en sí está abstraída de la elección del motor de ejecución. A la hora de escribir, Beam es capaz de compilar el mismo código del canal para dirigirse a Flink, Spark, Samza, GearPump, Google Cloud Dataflow y Apex. Esto le ofrece al usuario la opción de hacer evolucionar el motor de ejecución en un momento posterior sin alterar la implementación del trabajo. También está disponible un motor de ejecución «Direct Runner» para pruebas y desarrollo en el entorno local.
En 2016, el equipo de Flink introdujo Flink SQL. Kafka SQL se anunció en agosto de 2017 y, en mayo de 2019, un grupo de ingenieros de Apache Beam, Apache Calcite y Apache Flink entregó «Un SQL para gobernarlos a todos: un enfoque eficiente y sintácticamente idiomático para la gestión de streams y tablas» hacia un SQL de streaming unificado.
Hacia dónde nos dirigimos
Las herramientas disponibles para los arquitectos de software que diseñan el canal de datos siguen evolucionando a una velocidad cada vez mayor. Estamos observando motores de flujo de trabajo como Airflow y Prefect que integran sistemas como Dask para permitir a los usuarios paralelizar y programar cargas de trabajo masivas de aprendizaje automático en el clúster. Competidores emergentes como Apache Pulsar y Pravega están compitiendo con Kafka para abordar la abstracción del almacenamiento del stream. También estamos observando proyectos como Dagster, Kafka Connect y Siddhi que integran componentes existentes y presentan enfoques innovadores para visualizar y diseñar el canal de datos. El rápido ritmo de desarrollo en estas áreas hace que sea un momento muy emocionante para desarrollar aplicaciones intensivas en datos.
Si le interesa trabajar con este tipo de tecnologías, le animamos a que se ponga en contacto con nosotros. Estamos contratando a personal para varios puestos de ingeniería y en múltiples ubicaciones.

Robert Boyd es ingeniero principal de Software en Barracuda Networks. Su área de enfoque actual es el almacenamiento seguro y la búsqueda de correos electrónicos a gran escala.
Los favoritos de los lectores de 2021
El final del año siempre es un excelente momento para mostrar algunos de nuestros contenidos favoritos. Estas son las entradas de blog de Barracuda más populares de 2020. ¡Esperamos que las disfruten!
Ransomware y filtraciones de datos
- Cómo emplean los hackers el phishing en ataques de ransomware
- Principales preocupaciones que tienen las organizaciones sanitarias sobre la copia de seguridad de Office 365
- 3 pasos críticos para protegerse contra el ransomware
- El ciberataque a Colonial Pipeline revela el impacto económico del ransomware
Investigación
- Tipos de amenazas de correo electrónico: phishing de URL
- Threat Spotlight: tendencias del ransomware
- Threat Spotlight: ataques con cebo
Informes especiales
- El estado de la seguridad de redes en 2021
- El estado de la seguridad de aplicaciones en 2021
- Redes en la nube: avanzando hacia la hipervelocidad
- El estado de la copia de seguridad de Office 365
- Información sobre el creciente número de ataques automatizados
Bajo la superficie
- Bajo la superficie: por qué necesita una estrategia de copia de seguridad nativa de la nube
- Bajo la superficie: mujeres que avanzan en la tecnología
- Bajo la superficie: Perímetro de servicio de acceso seguro con Sinan Eren
Los gestores
- Barracuda fue nombrada visionaria en el Cuadrante Mágico de Gartner® de 2021
 sobre firewalls de red
sobre firewalls de red - Barracuda reconocida por Comparably por la mejor cultura empresarial
- 3 emocionantes innovaciones de productos anunciadas en Secured.21
- Entre bastidores de la colaboración entre Barracuda y Microsoft sobre Cloud-to-Cloud Backup
- Barracuda ha sido nombrada en la lista de Seguridad 100 de CRN de 2021
- Barracuda gana el premio al Mejor Servicio de Atención al Cliente en los SC Awards 2021
Antiguos favoritos
Algunas preguntas nunca desaparecen. ¿Por qué no puedo utilizar mi correo electrónico personal para el trabajo? ¿Qué quiere decir que este spam no es spam? Estas publicaciones son las favoritas de los lectores año tras año.
- Los riesgos empresariales de las cuentas de correo electrónico personales
- Ham contra spam: ¿cuál es la diferencia?
- Vectores de amenazas: ¿qué son y por qué necesita conocerlos?
Esperamos con ansias el 2022
Tendremos más contenido excelente de nuestros expertos, incluidos Olesia, Tushar, Anastasia, Jonathan, Fleming y otros. Publicamos varias veces a la semana y, si desea recibir notificaciones cuando tengamos contenido nuevo, suscríbase a nuestro blog para recibir resúmenes por correo electrónico de las últimas publicaciones. Los nuevos episodios de Bajo la superficie se emiten cada pocas semanas, y puede ver los episodios archivados en nuestra web.
Les deseamos lo mejor para el año nuevo, de parte de todos en Barracuda.

Christine Barry es la bloguera principal sénior y la directora de redes sociales en Barracuda. Antes de unirse a Barracuda, Christine fue ingeniera de campo y directora de proyectos para clientes de K12 y pymes durante más de 15 años. Posee varias credenciales en tecnología y gestión de proyectos, una licenciatura en Artes y un máster en Administración de Empresas. Se graduó en la Universidad de Michigan.
Conecte con Christine en LinkedIn aquí.
Registro de eventos altamente escalable en AWS
La mayoría de las aplicaciones generan eventos de configuración y de acceso. Es importante que los administradores tengan visibilidad de estos eventos. El servicio Barracuda Email Security proporciona transparencia y visibilidad de muchos de estos eventos para ayudar a los administradores a ajustar y comprender el sistema. Por ejemplo, saber quién ha iniciado sesión en la cuenta y cuándo. O saber quién ha añadido, cambiado o eliminado la configuración de una política específica.
Para construir este sistema distribuido y de búsqueda, se nos ocurren muchas preguntas, tales como:
- ¿Cómo debería usted escribir estos registros de todas las aplicaciones, servicios y máquinas en una ubicación central?
- ¿Cuál debería ser el formato estándar de los archivos de registro?
- ¿Durante cuánto tiempo debería conservar estos logs?
- ¿Cómo debería usted correlacionar eventos de diferentes aplicaciones?
- ¿Cómo le proporciona un mecanismo de búsqueda simple y rápido a través de una interfaz de usuario al administrador?
- ¿Cómo se hace que estos logs estén disponibles a través de una API?
Cuando piensa en un motor de búsqueda distribuido, lo primero que le viene a la mente es Elasticsearch. Es altamente escalable, con búsquedas casi en tiempo real y está disponible como un servicio totalmente gestionado en AWS. Así, el proceso comenzó con la idea de almacenar estos logs de eventos en Elasticsearch y que las diferentes aplicaciones le enviaran logs a Elasticsearch mediante Kinesis Data Firehose.
Componentes involucrados en esta arquitectura
- Kinesis Agent: Amazon Kinesis Agent es una aplicación de software Java independiente que ofrece una manera sencilla de recopilar y enviar datos a Kinesis Data Firehose. El agente supervisa continuamente los archivos de logs de eventos en las instancias de EC2 Linux y los envía al stream de entrega configurado de Kinesis Data Firehose. El agente gestiona la rotación de archivos, el punto de control y los reintentos en caso de fallos. Proporciona todos sus datos de manera fiable, puntual y sencilla. Nota: Si la aplicación que necesita escribir en Kinesis Firehose es un contenedor de Fargate, necesitará un contenedor de Fluentd. Sin embargo, este artículo se centra en las aplicaciones que se ejecutan en instancias EC2 de Amazon.
- Kinesis Data Firehose: el método de inserción directa de Amazon Kinesis Data Firehose puede escribir los datos en formato JSON en Elasticsearch. De esta manera, no se almacena ningún dato en el stream.
- S3: Se puede utilizar un bucket de S3 para hacer copias de seguridad de todos los registros o de los registros que fallen y no se entreguen a Elasticsearch. Las políticas de ciclo de vida también se pueden configurar para archivar automáticamente los logs.
- Elasticsearch: Elasticsearch alojado por Amazon. Se puede habilitar el acceso a Kibana para ayudarle a consultar y buscar los logs con cualquier finalidad de depuración.
- Curator: AWS recomienda usar Lambda y Curator para gestionar los índices y las instantáneas del clúster de Elasticsearch. AWS ofrece más detalles y ejemplos de implementación que se pueden encontrar aquí.
- Interfaz API REST: Puede crear una API como una abstracción para Elasticsearch que se integre bien con la interfaz de usuario. Se ha demostrado que las arquitecturas de microservicios impulsadas por API son las mejores en muchos aspectos, como la seguridad, el cumplimiento normativo y la integración con otros servicios.
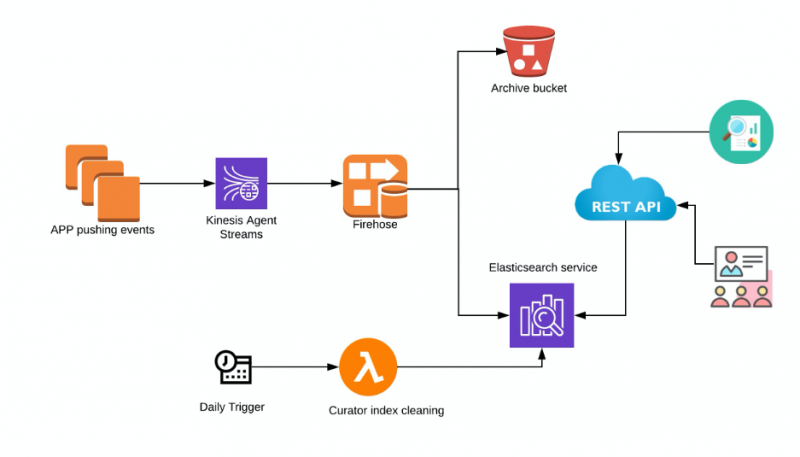
Escalado
- Kinesis Data Firehose: Por defecto, los streams de entrega de Kinesis Firehose pueden escalar hasta 1000 registros/seg o 1 MiB/seg para el este de EE. UU. (Ohio). Este es un límite flexible y se puede aumentar hasta 10 000 registros/seg. Esto es específico para cada región.
- Elasticsearch: el clúster de Elasticsearch puede escalarse tanto en términos de almacenamiento como de potencia de cómputo en AWS. También es posible actualizar la versión. Amazon ES utiliza un proceso de implementación azul/verde al actualizar los dominios. Esto significa que el número de nodos en el clúster podría aumentar temporalmente mientras se aplican sus cambios.
Ventajas de esta arquitectura
- La arquitectura del canal está completamente gestionada de manera efectiva y requiere muy poco mantenimiento.
- Si el clúster de Elasticsearch falla, Kinesis Firehose puede retener los registros hasta 24 horas. Además, también se realiza una copia de seguridad en S3 de los registros que fallen y no se entreguen.
Las probabilidades de pérdida de datos son bajas con estas opciones disponibles.
- El control de acceso detallado es posible tanto para la API de Kibana como para la de Elasticsearch a través de políticas de IAM.
Deficiencias
- Los precios deben considerarse y monitorizarse con atención. El Kinesis Data Firehose puede manejar grandes volúmenes de ingesta de datos con facilidad, y si un agente malintencionado comienza a registrar grandes cantidades de datos, el Kinesis Data Firehose los entregará sin inconvenientes. Esto puede ocasionar grandes costes.
- La integración de Kinesis Data Firehose con Elasticsearch solo se admite para clústeres de Elasticsearch que no sean VPC.
- Actualmente, Kinesis Data Firehose no puede entregar registros a clústeres de Elasticsearch que no estén alojados por AWS. Si desea autohospedar clústeres de Elasticsearch, esta configuración no funcionará.
Conclusión
Si busca una solución completamente gestionada que se escale (en su mayoría) sin intervención, esta sería una buena opción a considerar. La copia de seguridad automática en S3 con políticas de ciclo de vida también soluciona con facilidad el problema de retención y archivo de logs.

Sravanthi Gottipati es Gerente de Ingeniería de Email Security en Barracuda Networks. Puede conectar con ella en LinkedIn aquí.
DJANGO-EB-SQS: Una manera más sencilla de que las aplicaciones de Django se comuniquen con AWS SQS.
Los servicios de AWS, como Amazon ECS, Amazon S3, Amazon Kinesis, Amazon SQS y Amazon RDS, se utilizan extensamente en todo el mundo. Aquí en Barracuda, utilizamos AWS Simple Queue Service (SQS) para gestionar la mensajería dentro y entre los microservicios que hemos desarrollado en el framework de Django.
AWS SQS es un servicio de cola de mensajes que puede «enviar, almacenar y recibir mensajes entre componentes de software a cualquier volumen, sin perder mensajes ni requerir que otros servicios estén disponibles». SQS está diseñado para ayudar a las organizaciones a desacoplar aplicaciones y escalar servicios, y fue la herramienta perfecta para nuestro trabajo en microservicios. Sin embargo, cada nuevo microservicio basado en Django o el desacoplamiento de un servicio existente mediante AWS SQS requería que duplicáramos nuestro código y lógica para comunicarnos con AWS SQS. Esto dio lugar a una gran cantidad de código repetido y animó a nuestro equipo a crear esta biblioteca de GitHub: DJANGO-EB-SQS
Django-EB-SQS es una biblioteca de Python diseñada para ayudar a los desarrolladores a integrar rápido AWS SQS con aplicaciones existentes y/o nuevas basadas en Django. La biblioteca se encarga de las siguientes tareas:
- Serialización de los datos
- Incorporación de lógica de retrasos
- Sondeo continuo desde la cola
- Deserialización de los datos según los estándares de AWS SQS y/o uso de bibliotecas de terceros para comunicarse con AWS SQS.
En resumen, abstrae toda la complejidad involucrada en la comunicación con AWS SQS y permite que los desarrolladores se centren únicamente en la lógica empresarial central.
La biblioteca se basa en Django ORM framework y boto3 library.
Cómo lo utilizamos
Nuestro equipo trabaja en una solución de protección del correo electrónico que utiliza inteligencia artificial para detectar spear phishing y otros ataques de social engineering. Nos integramos con la cuenta de Office 365 de nuestros clientes y recibimos notificaciones cada vez que reciben nuevos correos electrónicos. Una de las tareas es determinar si el nuevo correo electrónico está libre de cualquier tipo de fraude. Al recibir dichas notificaciones, uno de nuestros servicios (Figura 1: Servicio 1) se comunica con Office 365 a través de Graph API y obtiene esos correos electrónicos. Para el procesamiento adicional de esos correos electrónicos y para que estén disponibles para otros servicios, esos correos electrónicos se envían a la cola de AWS SQS (Figura 1: queue_1).
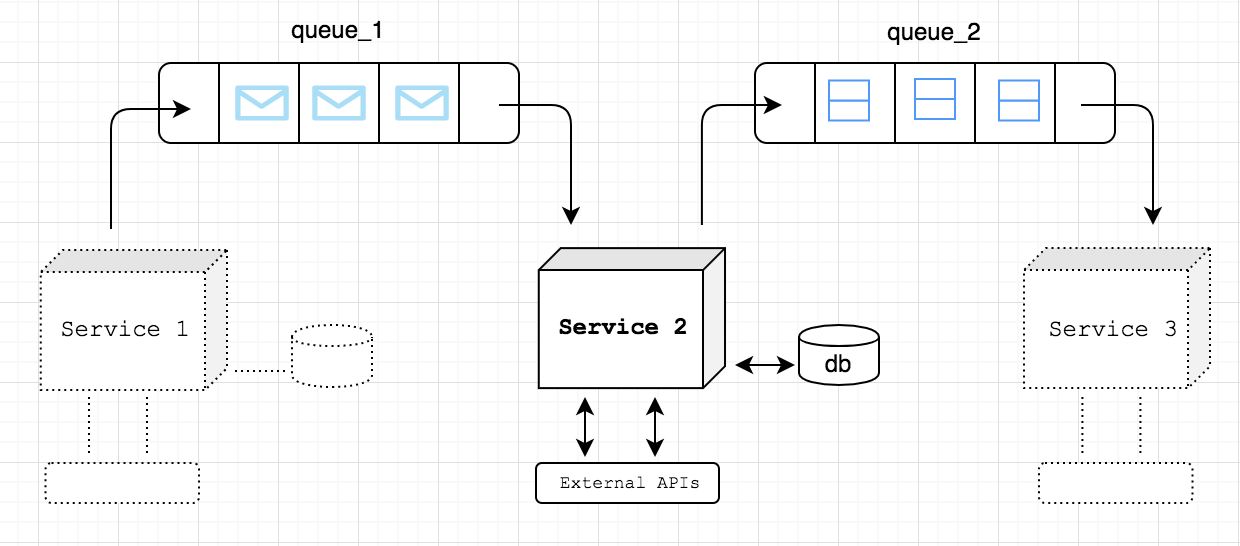
FIGURA 1
Examinemos un caso de uso sencillo sobre cómo usamos la biblioteca en nuestras soluciones. Uno de nuestros servicios (Figura 1: Servicio 2) es responsable de extraer encabezados y conjuntos de características de correos electrónicos individuales y ponerlos a disposición de otros servicios para su consumo.
El Servicio 2 está configurado para escuchar queue_1 y recuperar los cuerpos de correos electrónicos en bruto.
Supongamos que el Servicio 2 realiza las siguientes acciones:
# consumir mensajes de correo electrónico de queue_1
…
# extraer encabezados y conjuntos de características de los correos electrónicos
…
# enviar una tarea
process_message.delay(tenant_id=, correo electrónico=, headers=, tenant_id=, feature_set=, ....)
Este método process_message no se llamará de forma sincrónica, sino que se pondrá en cola como una tarea y se ejecutará una vez que uno de los trabajadores la recoja. El trabajador aquí podría ser del mismo servicio o de un servicio diferente. Quien llama el método no debe preocuparse por el comportamiento subyacente ni por cómo se ejecutará la tarea.
Veamos cómo se define el método process_message como una tarea.
Desde la tarea de importación eb_sqs.decorators
@task(queue_name='queue_2′, max_retries=3)
def process_message(tenant_id: int, email_id: str, headers: List[dict], feature_set: List[dict], …) :
pruebe a:
# realizar alguna acción utilizando encabezados y conjuntos de características
# también puede poner en cola tareas adicionales, si es necesario
except(OperationalError, InterfaceError) como exc:
pruebe a:
process_message.retry()
excepto MaxRetriesReachedException:
logger.error(‘MaxRetries reached for Service2:process_message ex: {exc}')
Cuando decoramos el método con el decorador de tareas, lo que sucede internamente es que se añaden datos adicionales, como el método de llamada, el método de destino, sus argumentos y algunos metadatos adicionales antes de serializar el mensaje y enviarlo a la cola de AWS SQS. Cuando el mensaje es consumido de la cola por uno de los trabajadores, este tiene toda la información necesaria para ejecutar la tarea: qué método llamar, qué parámetros pasar, etcétera.
También podemos volver a intentar realizar la tarea en caso de una excepción. Sin embargo, para evitar un escenario de bucle infinito, podemos establecer un parámetro opcional max_retries para detener el procesamiento cuando alcancemos el número máximo de reintentos. A continuación, podemos registrar el error o enviar la tarea a una cola de mensajes muertos para su posterior análisis.
AWS SQS ofrece la capacidad de retrasar el procesamiento del mensaje hasta 15 minutos. Podemos añadir una capacidad similar a nuestra tarea pasando el parámetro delay:
process_message.delay(email_id=, headers=, …., delay=300) # delaying by 5 min
La ejecución de las tareas se puede lograr ejecutando el comando process_queue de Django. Esto permite la escucha de una o más colas, la lectura de las colas de manera indefinida y la ejecución de las tareas a medida que llegan:
python manage.py process_queue –queues
Acabamos de ver cómo esta biblioteca facilita la comunicación dentro de un servicio o entre servicios a través de las colas de AWS SQS.
Puede encontrar más detalles sobre cómo configurar la biblioteca con los ajustes de Django, la capacidad de escuchar múltiples colas, la configuración de desarrollo y muchas más características aquí.
Contribuir
Si desea contribuir al proyecto, haga referencia a: DJANGO-EB-SQS

Rohan Patil es Ingeniero Principal de Software en Barracuda Networks. Actualmente, está trabajando en Barracuda Sentinel, una protección basada en IA contra el phishing y la usurpación de cuentas. Ha trabajado durante los últimos cinco años en tecnologías en la nube y en la última década en varios roles relacionados con el desarrollo de software. Tiene un máster en Informática por la Universidad Estatal de California y se licenció en Informática en Bombay (India).
Uso de GraphQL para APIs robustas y flexibles
El diseño de API es un área en la que puede haber mucha disputa entre los desarrolladores de aplicaciones cliente y los desarrolladores de backend. Las API REST nos han permitido diseñar servidores sin estado y un acceso estructurado a los recursos durante más de dos décadas, y siguen sirviendo a la industria, principalmente debido a su simplicidad y curva de aprendizaje moderada.
REST se desarrolló alrededor del año 2000, cuando las aplicaciones cliente eran relativamente simples y el ritmo de desarrollo no era tan rápido como lo es hoy en día.
Con un enfoque tradicional basado en REST, el diseño se basaría en el concepto de recursos que gestiona un servidor específico. Luego, normalmente confiaríamos en los verbos HTTP como GET, POST, PATCH, DELETE para realizar operaciones CRUD en esos recursos.
Desde la década de los 2000, varias cosas han cambiado:
- El aumento del uso de aplicaciones de una sola página y aplicaciones móviles ha creado la necesidad de una carga de datos eficiente.
- Muchas de las arquitecturas de backend han pasado de arquitecturas monolíticas a arquitecturas de microservicios para ciclos de desarrollo más rápidos y eficientes.
- Se necesita una variedad de clientes y consumidores para las API. REST dificulta la creación de una API que soporte múltiples clientes, ya que devolvería una estructura de datos fija.
- Las empresas esperan desplegar las características más rápido en el mercado. Si es necesario realizar un cambio en el lado del cliente, a menudo se requiere un ajuste en el lado del servidor con REST, lo que lleva a ciclos de desarrollo más lentos.
- El aumento de la atención a la experiencia del usuario a menudo lleva a diseñar vistas/widgets que requieren datos de múltiples servidores de recursos de la API REST para renderizarlas.
GraphQL como una alternativa a REST
GraphQL es una alternativa moderna a REST que busca resolver varias deficiencias, y su arquitectura y herramientas están diseñadas para ofrecer soluciones a las prácticas contemporáneas de desarrollo de software. Permite a los clientes especificar exactamente qué datos son necesarios y permite obtener datos de múltiples recursos en una única solicitud. Funciona más como RPC, con consultas nombradas y mutaciones en lugar de acciones obligatorias estándar basadas en HTTP. Esto sitúa el control donde corresponde: el desarrollador de la API de backend especifica lo que es posible, y el cliente/consumidor de la API especifica lo que se requiere.
Aquí tiene un ejemplo de consulta de GraphQL, que fue revelador para mí cuando lo encontré por primera vez. Supongamos que estamos desarrollando un sitio web de microblogging y necesitamos consultar 50 publicaciones recientes.
query recentPosts(count: 50, offset: 0) {
id
title
tags
content
author {
id
name
profile {
email
interests
}
}
}
La consulta GraphQL mencionada anteriormente tiene como objetivo solicitar:
- 50 publicaciones recientes
- ID, título, etiquetas y contenido de cada entrada de blog
- Información del autor que incluye ID, nombre e información de perfil.
Si tenemos que utilizar un enfoque tradicional de API REST para esto, el cliente tendría que hacer 51 solicitudes. Si las publicaciones y los autores se consideran recursos separados, se realiza una solicitud para obtener 50 publicaciones recientes y luego 50 solicitudes para obtener la información del autor de cada publicación. Si la información del autor puede incluirse en los detalles de la publicación, entonces esto también podría ser una solicitud con la API REST. Sin embargo, en la mayoría de los casos, cuando modelamos nuestros datos utilizando las mejores prácticas de normalización de bases de datos relacionales, gestionaríamos la información del autor en una tabla separada, lo que convierte la información del autor en un recurso de API REST independiente.
Esta es la parte interesante de GraphQL. Supongamos que en una vista móvil, no disponemos de espacio en la pantalla para mostrar tanto el contenido de la publicación como la información del perfil del autor. Esa consulta ahora podría ser:
query recentPosts(count: 50, offset: 0) {
id
title
tags
author {
id
name
}
}
El cliente móvil ahora especifica la información que desea, y la API de GraphQL proporciona exactamente los datos que se solicitan, ni más ni menos. No tuvimos que hacer ningún ajuste en el lado del servidor, ni nuestro código del lado del cliente tuvo que cambiar significativamente, y el tráfico de red entre el cliente y el servidor es óptimo.
El punto a tener en cuenta aquí es que GraphQL nos permite diseñar APIs flexibles basadas en los requisitos del lado del cliente en lugar de desde la perspectiva de la gestión de recursos del lado del servidor. Una percepción general es que GraphQL solo tiene sentido para arquitecturas complejas que implican varias decenas de microservicios. Esto es verdad hasta cierto punto, dado que hay una curva de aprendizaje con GraphQL en comparación con las arquitecturas de API REST. Pero esa brecha se está cerrando, con una importante inversión intelectual y financiera de la emergente fundación de proveedores neutrales.
Barracuda es pionera en la adopción de arquitecturas GraphQL. Si este blog ha despertado su interés, siga este espacio para ver mis próximas publicaciones, donde profundizaré en más detalles técnicos y beneficios arquitectónicos.

Vinay Patnana es el director de ingeniería del Servicio de Seguridad del Correo Electrónico de Barracuda. En este puesto, ayuda en el diseño y desarrollo de los servicios de escalabilidad de las soluciones de correo electrónico de Barracuda.
Vinay tiene un máster en Informática por la Universidad Estatal de Carolina del Norte y una licenciatura en Ingeniería por el BIT Mesra, India. Lleva varios años en Barracuda y tiene más de una década de experiencia laboral con distintas variedades de pilas tecnológicas. Puede conectar con él en LinkedIn aquí.
Nota: Este artículo fue publicado originalmente en el Databricks Company Blog.
El 74 % de las organizaciones a nivel mundial han sido víctimas de un ataque de phishing. Barracuda Networks es líder mundial en soluciones de seguridad, entrega de aplicaciones y protección de datos, ayudando a los clientes a combatir los ataques de phishing a gran escala. Barracuda ha creado un potente motor de inteligencia artificial que utiliza el análisis del comportamiento para detectar ataques y mantener a raya a los actores maliciosos.
Gestionar los correos electrónicos de phishing es complicado debido a la sofisticación que emplean los atacantes al crear correos electrónicos maliciosos en la actualidad. Barracuda Networks utiliza el aprendizaje automático para evaluar e identificar mensajes maliciosos y proteger a sus clientes. Al utilizar el aprendizaje automático en la plataforma Lakehouse de Databricks, el equipo de Barracuda ha podido avanzar mucho más rápido y ahora bloquea decenas de miles de correos electrónicos maliciosos a diario para que no lleguen a millones de buzones de miles de clientes.
Proporcionando una protección del correo electrónico integral
El equipo de Barracuda se dedica a detectar los ataques de phishing y a ofrecer seguridad a los clientes. Lo logra trabajando sobre Microsoft Office 365 y analizando el stream de correos electrónicos para detectar cualquier posible amenaza. Si se detecta un ataque, se elimina inmediatamente del buzón antes de que los usuarios puedan verlo.
protección contra la suplantación de identidad
Uno de los productos clave que ofrece Barracuda es la protección contra la suplantación de identidad. La suplantación de identidad ocurre cuando actores maliciosos disfrazan sus mensajes para que parezcan provenir de una fuente oficial, como un ejecutivo o servicio conocido. Los atacantes pueden utilizar este ataque para acceder a información confidencial, lo que representa un riesgo significativo tanto para los particulares como para las organizaciones.
La protección contra la suplantación de identidad se centra en prevenir los ataques de phishing dirigidos. Estos intentos no se envían en grandes cantidades, a diferencia de los correos electrónicos de spam. Para enviar un ataque dirigido, el atacante debe tener datos personales del destinatario para personalizarlo, como su profesión o campo laboral. Para identificar y bloquear los ataques de phishing por suplantación de identidad, el equipo tuvo que desarrollar un conjunto de modelos de clasificación e implementarlos en producción para nuestros usuarios.
Dificultades con la ingeniería de características
Para entrenar correctamente nuestros modelos de IA para detectar ataques de phishing y suplantación de identidad, Barracuda necesitaba utilizar los datos adecuados y realizar ingeniería de características sobre esos datos. Los datos incluían texto de correo electrónico, que podría ser una señal de un ataque de phishing, y datos estadísticos, como los detalles del remitente del correo electrónico. Por ejemplo, si un usuario recibe un correo electrónico de factura de alguien que no ha enviado un correo similar en los últimos meses, esto podría señalar un riesgo de ataque de phishing. Antes de la integración de Databricks, la construcción de características era más complicada con los datos etiquetados distribuidos a lo largo de varios meses, especialmente en el caso de las características estadísticas. Además, realizar un seguimiento de las características es un desafío, ya que nuestro conjunto de datos ha crecido en tamaño.
Implementación lenta
Nuestro equipo mantuvo el código y el modelo separados y tuvo que duplicar el código de investigación para el entorno de producción, lo cual requirió tiempo y energía. Primero pasaríamos cada correo electrónico entrante por el código de preprocesamiento y luego pasaríamos los correos preprocesados al modelo para su inferencia.
Barracuda encuentra el éxito utilizando Databricks
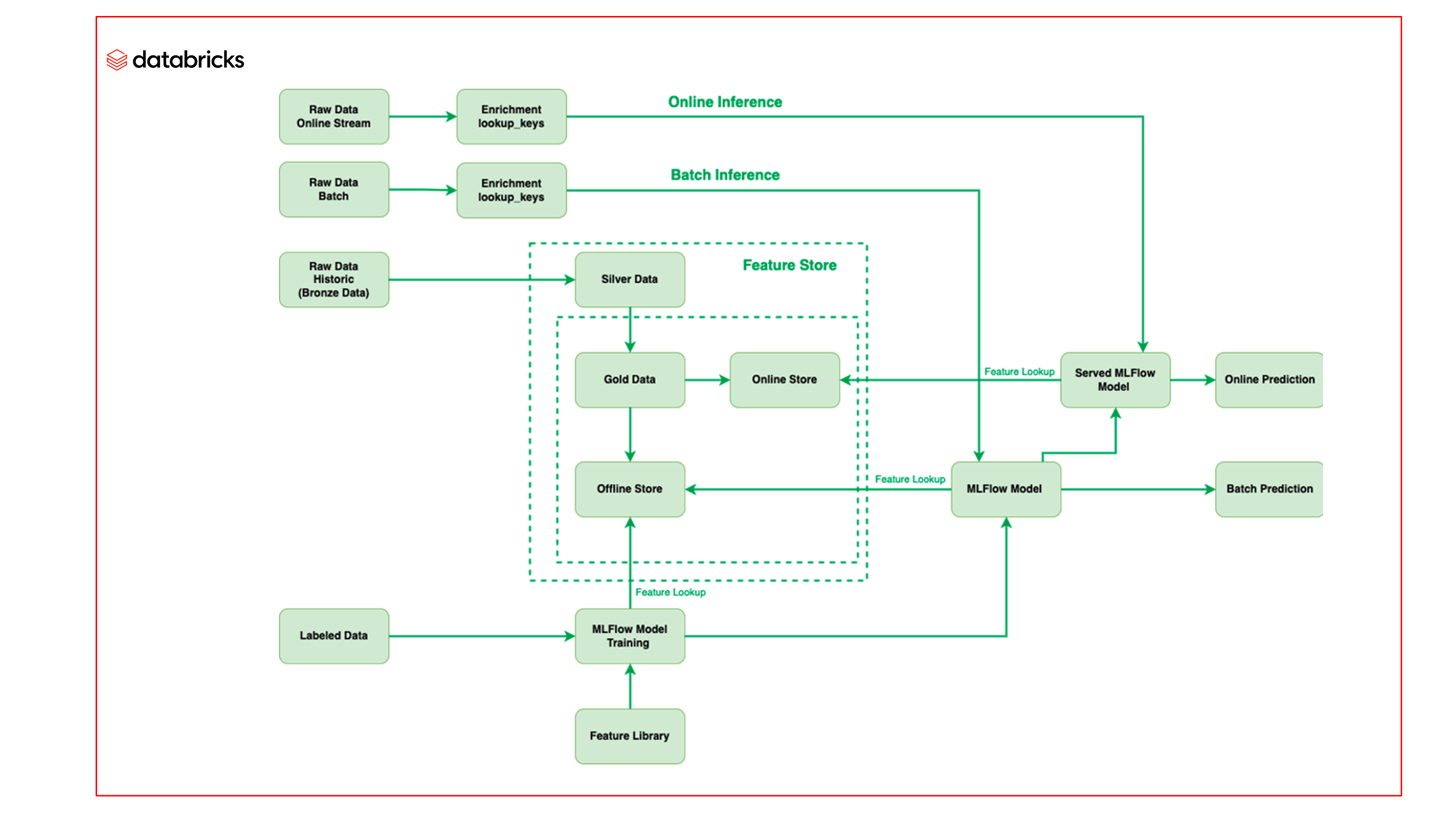
El equipo de Barracuda aprovechó el aprendizaje automático en la Databricks Lakehouse Platform, específicamente utilizando la Feature Store de Databricks y Managed MLflow, para mejorar el proceso de aprendizaje automático e implementar modelos de mejor calidad con mayor rapidez.
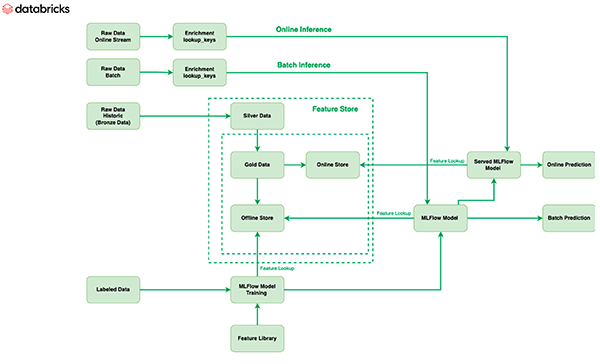
Feature Store
La Feature Store de Databricks actúa como el único repositorio para todas las características utilizadas por el equipo de Barracuda. Para crear y mantener características estadísticas que se actualizan constantemente con nuevos lotes de correos electrónicos entrantes, se emplearon datos etiquetados en la ingeniería de características. Debido a que la Feature Store se basa en Delta, no se requiere ningún procesamiento adicional para convertir los datos etiquetados en características, y las características permanecen actualizadas. Las características se almacenan en un repositorio offline, y luego se publican instantáneas de esta información online para su uso en inferencias online. Además, al integrar la Feature Store de Databricks con MLflow, estas características se pueden llamar fácilmente desde los modelos en MLflow, y el modelo puede obtener la característica al mismo tiempo que se recupera cuando llega el correo electrónico para la inferencia.
Operaciones de aprendizaje automático más rápidas
La otra ventaja es gestionar todos los modelos de aprendizaje automático en MLflow. Con MLflow, el equipo puede trasladar todo el código al interior del modelo; por lo tanto, puede permitir que el correo pase por el modelo para inferir, en lugar de preprocesarlo a través del código como se hacía antes, lo que simplifica y acelera el proceso de inferencia. Utilizando MLflow, el equipo de Barracuda es capaz de construir modelos completamente autoempaquetados. Esta capacidad reduce significativamente el tiempo que el equipo dedica a desarrollar modelos de aprendizaje automático.
Mayor tasa de detección
Con Databricks, el equipo dispone de más tiempo y más capacidad de cálculo, lo que les permite publicar una nueva tabla con frecuencia en Delta, actualizar las características a diario y utilizarlas para determinar si un correo electrónico entrante es un ataque o no. Esto resulta en una mayor precisión en la detección de ataques de phishing y mejora la protección y satisfacción del cliente.
Impacto
Con la ayuda de Databricks, Barracuda protege a los usuarios de ataques por correo electrónico en todo el mundo. Cada día, el equipo bloquea decenas de miles de correos electrónicos maliciosos para que no lleguen a las bandejas de entrada de los clientes. El equipo está deseando seguir implementando nuevas características de Databricks para mejorar aún más la experiencia de nuestros clientes.

{kind=link}
Mohamed Afifi Ibrahim es Ingeniero Principal de Aprendizaje Automático en Barracuda.